개인 블로그를 만들면서 배운 것들
개인 블로그를 만들면서 “어떻게 콘텐츠를 관리할지?”에 대한 고민과 선택의 과정을 기록했습니다.
블로그를 만들게된 배경
예전부터 개인 기술 블로그하나 갖고싶다는 생각을 하고 있었다. 하지만 회사 일, 사이드 프로젝트, 이것저것 하다 보니 자연스레 잊고 지냈다. (게을러서 그럼)
나는 최근까지 velog를 사용했었다. 내가 velog를 사용한 이유는 국내에서 유일한 개발자용 블로그였고, 글도 마크다운으로 쉽게 작성할 수 있었다는 장점이 있었다.
하지만 요즘은 벨로그는 예전 같지 않은것 같다. 초반엔 글의 질도 좋고 커뮤니티도 활발했는데 지금은 스팸성 글이나 광고가 많아지고 잘 정리된 기술 포스트를 찾기가 어려웠다.
티스토리로 옮길까도 고민했었지만 커스터마이징 과정이 번거로웠고, 디자인을 내 입맛에 맞추는 게 생각보다 귀찮았다. 이참에 직접 만들어보는 게 낫겠다는 생각이 들었다.!!

마침 찬규와 의찬이가 “각자 기술 블로그를 만들어보기”라는 스터디를 열어보자고 했고 좋은 기회라고 생각해서 이번에 확실히 끝내보기로 했다.
“어떻게 만들면 좋을까?”를 꽤 고민했는데, 항해플러스 9주차 과제에서 바닐라 JS와 React로 SSR과 SSG를 직접 구현한 과제를 토대로 그 과정을 조금 더 발전시켜 내 블로그를 완전히 직접 만들어보면 어떨까 하는 생각이 들었다. 과제를 복습할 수 있으면서, 기술적으로도 더 깊게 탐구해볼 수 있는 기회가 될 것 같았다.
하지만 스터디의 취지가 “명절 내에 완성해보자”였던 만큼, 짧은 기간 안에 완성도를 챙길 수 있는 방법을 선택해야 했다. 그래서 자연스럽게 Next.js를 사용하는 방식으로 방향을 잡았다.
준일님이 재미있는 아이디어도 주셨지만… 이번에는 시간과 목표를 고려해 다음 기회에 적용해보기로 했다.
그리고 준형님이 알려주신 하조은님의 “Vercel 기술 블로그 아키텍처 뜯어보기” 영상이 정말 큰 도움이 됐다.
아래는 내가 블로그를 만들면서 고민했던 과정과 생각들을 작성했다.
그래서 어떻게 만들건데?
블로그를 만드는 과정은 간단하게 이렇게 정리할 수 있다.
콘텐츠 저장소 → GET → 데이터 파싱/처리 → 정적 페이지 생성 → 배포여기서 가장 고민했던 부분은 “콘텐츠를 어떻게 관리할까?”였다.
짧은 기간 안에 블로그를 완성하려면, 단순히 페이지를 띄우는 것만이 아니라 글을 쓰고, 쓴 글을 관리하고, 기술적으로도 의미 있는 구조를 만들어야 했다.
그래서 세 가지 기준을 세웠다.
- 글 작성 경험이 좋아야 한다.
- 유지보수는 편해야 한다.
- 기술적으로 도전해볼만한 과제가 있어야 한다.
→ 글을 쓰는 과정이 귀찮거나 번거로워선 안 된다.
→ 글을 추가하거나 수정할 때 최소한의 작업으로 반영되어야 한다.
→ 단순히 가져다 쓰는 구조가 아니라, 구현 과정에서 개발자로서 배울 수 있는 요소가 있어야 한다.
결국, 콘텐츠 저장소를 어떻게 선택하느냐가 이 세 가지 목표를 만족시키는 핵심 관심사였다.
아래는 내가 고민한 3가지의 방법이다.
1. MDX 방식
가장 간단하고 익숙한 방식이다. /post 폴더 안에서 .mdx 파일을 넣어두고 빌드 타임에 이를 읽어서 정적 페이지로 변환하면 된다. 하지만 콘텐츠를 repo안에서 관리해야하다보니
- 글 작성 경험은 좋은가? ❌
- 유지보수는 편한가? ❌
→ 매번 IDE에서 글을 작성해야하거나, 노션에서 따로 옮겨서 복붙하는 구조로 작성해야했다.
→ 글 하나 작성/수정할 때마다 커밋 + 배포를 해야 한다.
결국 두가지 조건을 만족하지 못해서 과감히 PASS 했다.
2. Github repo를 DB로 쓰기
두번째 아이디어는 Github repo를 DB로 쓰는 아이디어였는데 이 아이디어는 찬규가 제시해줬다.

개념상으로는 꽤 흥미로웠다. Github repo를 DB로 사용해서 콘텐츠를 repo에 올려두고 Next에서는 Github API를 활용해서 데이터를 가지고 오는 구조였다.
하지만 개인적인 생각으로
- 글 작성 경험은 좋은가? ❌
- 유지보수는 편한가? 🔺
→ 이것 역시 github repo에서 바로 작성을 해서 올리거나, IDE를 켜서 작성을 해야한다. 혹은 다른 CMS에서 콘텐츠를 작성하고 복붙하는 방식으로 활용해야한다.
→ 인증 토큰, API rate limit, 캐시 처리 등 신경써야하는 부분들이 몇 가지 존재했다.
3. Notion을 DB로 쓰기 (채택)
최종적으로 채택한 방식은 Notion을 DB로 사용하는 방법이였다.
- 글 작성 경험은 좋은가? ✅
- 유지보수는 편한가? ✅
- 기술적으로 도전해볼만한 과제가 있는가? ✅
→ 평소 회고나 기술블로그를 쓸 때 노션을 자주 사용했기 때문에 글쓰기 경험이 익숙해고 편리했다.
→ Notion으로 데이터베이스만 관리하기 때문에 테이블 설계를 잘하면 관리하기 편하게 설계할 수 있을것 같았다.
→ 이미지 만료 관련된 이슈들이 존재했어서 이 부분도 기술적으로 해결해보면 재밌을것 같다는 생각을 했다.
이 세가지 조건을 만족했기 때문에 과감히 Notion을 콘텐츠 저장소로 사용하기로 했다.
콘텐츠 저장소를 Notion으로 써보자
Headless CMS
우선 블로그 콘텐츠를 Notion에서 관리할 수 있게 테이블을 설계했다.
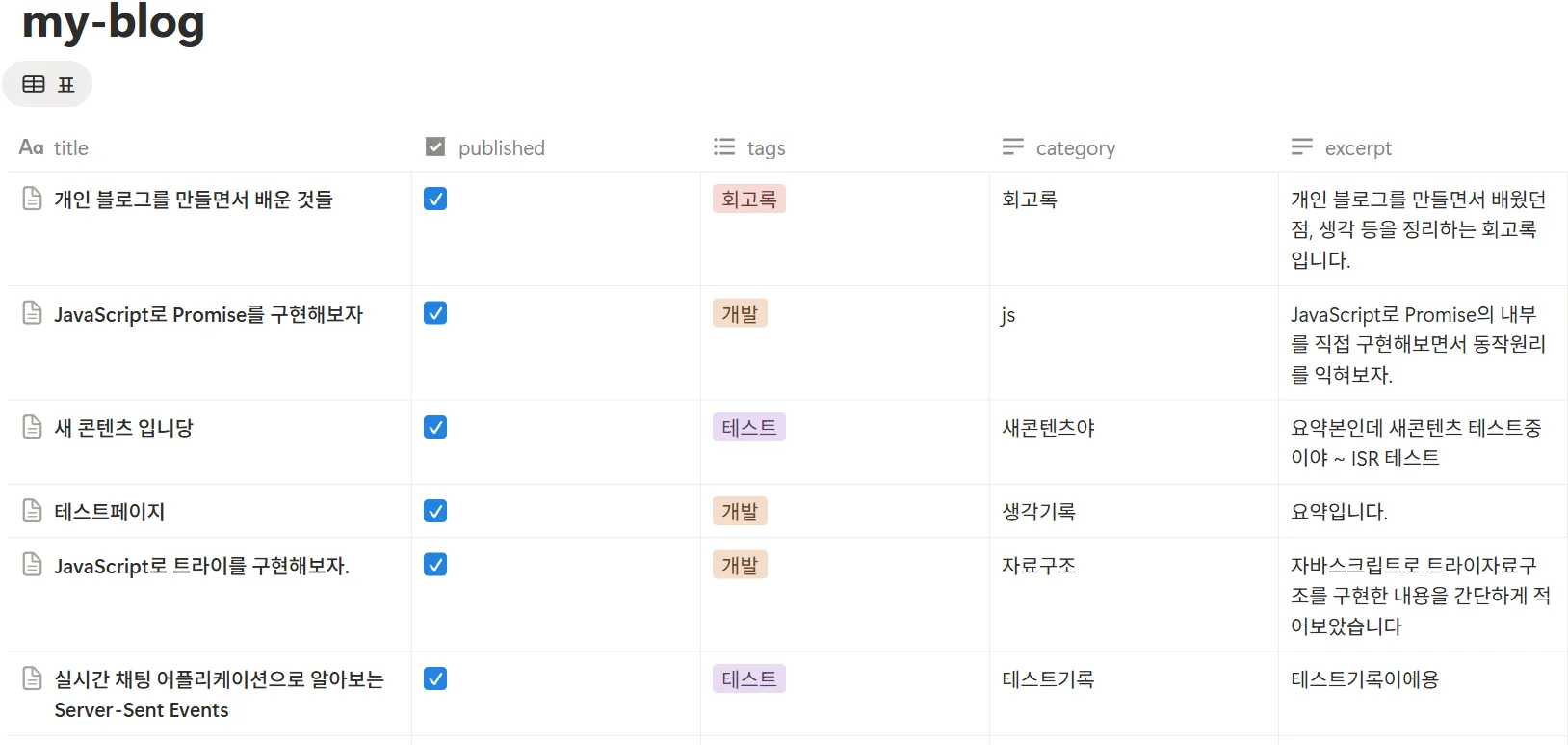
위 그림처럼 published라는 체크박스를 만들어서 새로운 콘텐츠를 배포하는 식으로 간단하게 구현했고 코드상으로는 published가 true인 콘텐츠만 가지고 오는 방식으로 구현했다.
이 방식 덕분에 글을 쓰는 환경과 여러 콘텐츠에 대한 관리(임시 작성용이라던지, 수정 중인 콘텐츠)를 Notion 내에서 바로 해결하여 Headless CMS 환경을 구축할 수 있었다.
마크다운 파서 만들기
정확히 말하면 "마크다운 파서"라기보다는 "Notion 블록 파서" 에 가까웠다. Notion API는 콘텐츠를 마크다운이 아닌 블록(Block) 단위로 반환하기 때문에, 이를 우리가 원하는 형태로 변환하는 작업이 필요했다.
Notion에서 받아오는 데이터는 대략 이런 구조이다.
{
id: "block-id",
type: "paragraph", // heading_1, code, image 등
paragraph: {
rich_text: [
{
plain_text: "실제 텍스트",
annotations: { bold: true, italic: false, ... },
href: null
}
]
}
}각 블록 타입(paragraph, heading_1, code, image 등)마다 데이터 구조가 다르기 때문에 이를 일관되게 처리할 수 있는 파싱 레이어가 필요했다.
Parser 만들기
나는 Notion 블록을 React 컴포넌트로 렌더링하기 위해 총 3단계의 작업을 거쳤다.
1단계: Notion에서 block데이터 가지고 오기 Notion API는 한번에 최대 100개의 블록만 반환하므로 페이지네이션 처리가 필요했다. 그리고 각 블록에서 필요한 정보들만 뽑아서 공통된 인터페이스로 변환하는 작업을 해주었다.
export async function getPostBlocks(pageId: string): Promise<NotionBlock[]> {
const allBlocks: NotionBlock[] = [];
let cursor: string | undefined = undefined;
let hasMore = true;
// 모든 블록을 페이지네이션으로 가져오기
while (hasMore) {
const response = await getClient().blocks.children.list({
block_id: pageId,
page_size: 100,
start_cursor: cursor,
});
const blocks = response.results.map((block) => {
const notionBlock = block as NotionBlockType;
return {
id: notionBlock.id,
type: notionBlock.type,
content: extractBlockContent(notionBlock),
children: notionBlock.has_children ? [] : undefined,
};
});
allBlocks.push(...blocks);
hasMore = response.has_more;
cursor = response.next_cursor || undefined;
}
return allBlocks;
}2단계: 블록 타입별 데이터 추출
1단계에서 필요한 데이터만 추출했으면 2단계에선 해당 데이터를 정규화 하는 작업이 필요했다.
Notion API 응답은 매우 복잡했는데 paragraph 블록이든, heading_2 블록이든, 텍스트 콘텐츠가 들어있는 부분의 구조가 조금씩 다르고, 심지어 그 텍스트마저도 단순 문자열이 아니라 볼드, 링크 같은 스타일 정보가 담긴 '리치 텍스트(Rich Text)' 배열로 들어왔다.
일단 간단하게 순수 콘텐트만 뽑아내는 함수를 구현했다.
/**
* Notion 블록의 content에서 순수 텍스트를 추출
*/
export function extractText(content: NotionBlock["content"]): string {
// ... (앞부분: 타입 가드 및 단순 문자열 처리)
if (typeof content === "object" && content !== null) {
const textContent = content as TextContent;
// 만약 content 안에 rich_text 배열이 있다면?
if ("rich_text" in textContent && textContent.rich_text) {
// 🌟 핵심: 배열을 순회하면서 'plain_text' 속성만 싹 다 긁어모아 합쳐 버린다!
return textContent.rich_text.map((item: RichTextItem) => item.plain_text || "").join("");
}
}
return "";
}이 코드는 복잡한 리치 텍스트 배열을 뜯어서 그 안에 있는 순수한 텍스트들만 쏙 빼낸다음 한줄의 문자열로 만들어주는 함수이다.
두번째로는 볼드 처리된 부분은 볼드로, 링크는 클릭 가능한 형태로 살리기위해 스타일 정보가 담긴 원래의 리치 텍스트 배열 자체가 필요했다. 이 배열을 기반으로 렌더링을 해야 실제 마크다운처럼 렌더링을 할 수 있다.
/**
* Rich text 배열 추출 (볼드, 이탤릭 등 스타일 정보 포함)
*/
export function extractRichTextArray(content: NotionBlock["content"]): RichTextItem[] {
if (typeof content === "object" && content !== null) {
const textContent = content as TextContent;
// 🌟 리치 텍스트 배열이 있다면, 다른 거 건드리지 않고 그대로 반환!
if ("rich_text" in textContent && textContent.rich_text) {
return textContent.rich_text;
}
}
return [];
}이렇게 두가지를 분리한 이유는 순수한 텍스트가 필요할 때(목차같은것들)와 서식이 입혀진 데이터가 필요할 때를 명확하게 구분할 수 있게 구현했다.
3단계: 렌더링 가능한 형태로 맵핑
1단계에서 복잡한 Notion 블록들을 싹 긁어왔고, 2단계에서 extractText와 extractRichTextArray 함수로 필요한 데이터를 깔끔하게 정규화해뒀다.
이제 이 정규화된 데이터를 가지고 실제 React 컴포넌트에서 써먹기 좋은 형태로 최종 변환하는 작업이 필요했다.
Notion 블록은 여전히 type: "heading_1", type: "paragraph"처럼 Notion이 정의한 문자열을 가지고 있다.
하지만 React 컴포넌트를 만들 때는 H1Block 컴포넌트, ParagraphBlock 컴포넌트처럼 내가 원하는 속성(Props)을 가진 객체로 변환하는 작업을 거쳤다.
우선 Notion의 복잡한 데이터 구조를 직접 다루는 대신 내가 필요한 Props만 다룰 수 있게 타입들을 정의했다.
이렇게 타입을 명시적으로 만들어두면, 나중에 컴포넌트를 만들 때 불필요한 에러들을 1차적으로 거를 수 있었다.
// ParsedBlock 인터페이스 예시
export interface ParsedParagraphBlock {
type: "paragraph";
richText: RichTextItem[];
fallbackText: string;
}
export interface ParsedListBlock {
type: "bulleted_list_item" | "numbered_list_item";
richText: RichTextItem[];
fallbackText: string;
}
export interface ParsedCodeBlock {
type: "code";
code: string; // 순수 코드 텍스트
language: string; // 하이라이팅을 위한 언어 정보
}
export interface ParsedQuoteBlock {
type: "quote";
richText: RichTextItem[];
fallbackText: string;
}
export interface ParsedImageBlock {
type: "image";
url?: string; // 이미지 주소
caption?: string; // 이미지 설명
}이제 parseNotionBlock 함수를 구현했는데 이 함수는 Notion 블록을 받아서 내가 작성한 타입중 하나로 변환시켜주는 역할을 한다.
export function parseNotionBlock(block: NotionBlock): ParsedBlock {
const { type, content } = block;
const richText = extractRichTextArray(content);
const fallbackText = extractText(content);
switch (type) {
case "paragraph":
return {
type: "paragraph",
richText,
fallbackText,
};
case "heading_1":
case "heading_2":
case "heading_3":
return {
type,
richText,
fallbackText,
level: parseInt(type.split("_")[1]) as 1 | 2 | 3,
};
case "code":
return {
type: "code",
code: fallbackText,
language: extractLanguage(content),
};
case "image":
const { url, caption } = extractImageData(content);
return {
type: "image",
url,
caption,
};
// ... 다른 블록 타입들
}
}이렇게 Mapper를 만들어 Notion의 복잡한 데이터를 최종적으로 일관된 인터페이스로 만드는 작업까지 완료했다. (전체 코드를 보면 굉장히 간단한 분기문으로 작성했다.)
React 컴포넌트로 렌더링을 해보자
이제 모든 준비가 끝났다.
API 레이어에서 데이터를 받아왔고 → Parser 레이어에서 데이터들을 정규화 했고 → Mapper 레이어에서 정규화된 데이터를 기반으로 Props를 뽑았다.
export function NotionBlockRenderer({ block, headingId }: NotionBlockRendererProps) {
// 1. Mapper를 통해 처리된 데이터를 받습니다.
const parsed = parseNotionBlock(block);
// 2. 텍스트 콘텐츠 렌더링을 위한 유틸리티 함수
const renderContent = () => {
// richText가 있다면 <RichTextRenderer> 컴포넌트에 넘겨서 렌더링합니다.
if ("richText" in parsed && parsed.richText.length > 0) {
return <RichTextRenderer items={parsed.richText} />;
}
return null;
};
// 3. 빈 블록 체크: Notion에서 엔터 친 것까지 표현해야 하니까 이렇게 처리
const isEmpty = "richText" in parsed && parsed.richText.length === 0;
switch (parsed.type) {
case "paragraph":
if (isEmpty) {
// 비어있는 블록은 줄바꿈 효과를 내기 위해서 추가
return <p className="mb-2 leading-relaxed" style={{ minHeight: "1em" }}></p>;
}
return <p className="mb-2 leading-relaxed text-gray-700 dark:text-gray-300">{renderContent()}</p>;
case "heading_1":
return (
// headingId를 받아서 목차(TOC) 생성을 위한 id를 붙여줍니다.
<h1 id={headingId} className="mb-6 text-3xl font-bold text-gray-900 dark:text-white">
{renderContent()}
</h1>
);
case "code":
// CodeBlock 컴포넌트에 코드 내용과 언어만 깔끔하게 넘깁니다.
return <CodeBlock code={parsed.code} language={parsed.language} />;
case "image":
// 이미지 처리도 전용 컴포넌트에 넘겨서 캡션과 URL을 처리하게 합니다.
return <ImageBlock url={parsed.url} caption={parsed.caption} />;
// ... 다른 블록 타입들도 각자의 전용 컴포넌트로 매핑됩니다.
}
}이 Mapper에서 반환된 props를 기반으로 렌더링을 해보자.
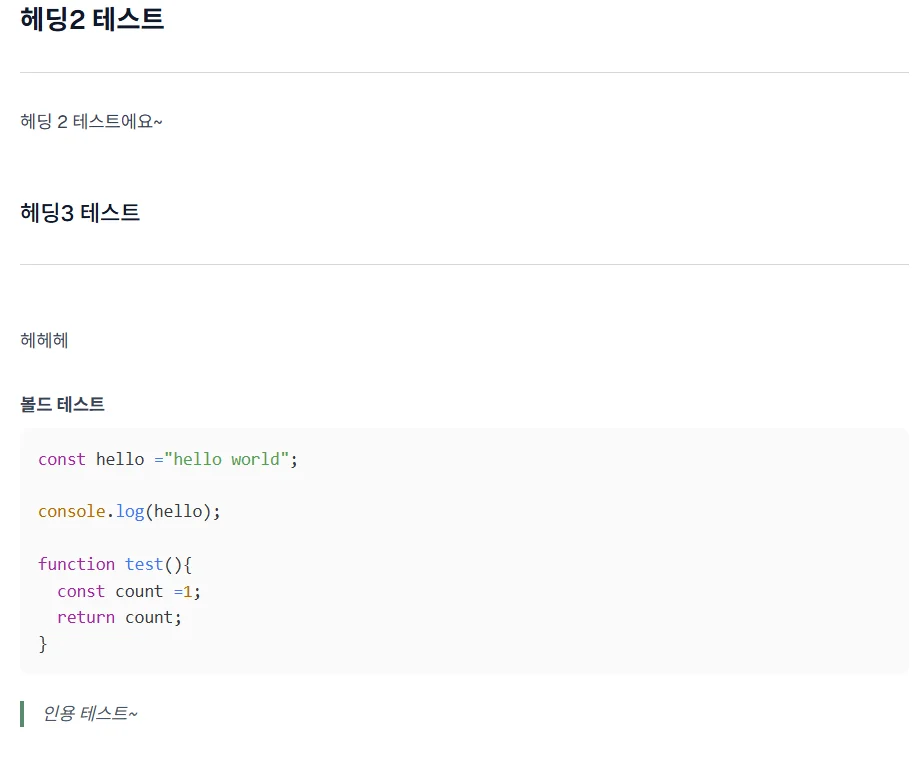
이렇게 마크다운 형태로 잘 나오는것을 확인할 수 있다.
Notion 이미지 만료 이슈 처리하기
Notion을 사용할 때 가장 큰 문제 중 하나는 이미지 URL이 1시간 후 만료된다는 점이었다. Notion에서 제공하는 이미지 URL은 AWS S3의 Signed URL이라 보안상의 이유로 짧은 유효기간을 가지고 있다.
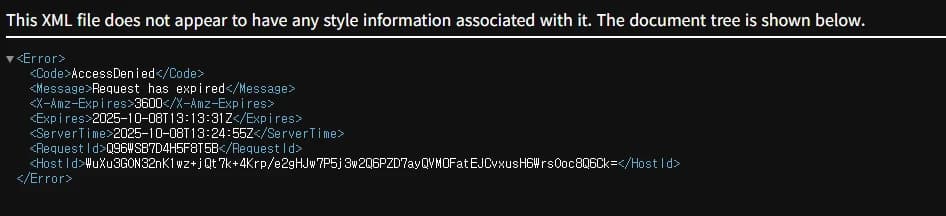
// Notion API가 반환하는 이미지 URL 예시
https://prod-files-secure.s3.us-west-2.amazonaws.com/...?X-Amz-Expires=3600이 문제를 해결하는 방법은 크게 세 가지가 있었다.
- 런타임에 프록시 서버를 통해 이미지 제공
- Notion의 공개 이미지 프록시 URL 사용
- 빌드 타임에 이미지를 다운로드해서 로컬에 저장 ✅
나는 3. 빌드 타임에 이미지를 다운로드해서 로컬에 저장 방식을 선택했다.
왜 방법 3을 선택했는가 정리를 해보자면
1. 성능이 중요하다
블로그의 핵심은 글을 읽는 경험이다. 이미지 로딩이 느리면 독자가 떠날 확률이 높아진다.
특히 한 글에 이미지가 10개 이상 있다면, 방법 3은 전체 로딩 시간을 수 초 단축시킬 수 있다.
사실 이제 처음 구축하는 블로그라 성능적인 이점을 고려할 필요는 없었는데 아까 초기 목표였던 “3. 기술적으로 도전해볼 만한 과제가 있는가?”를 달성해보기 위해 실험적으로 도입했다.
2. Vercel의 서버리스 환경에 최적화
Vercel은 서버리스 함수에 대해 실행 시간과 대역폭으로 과금한다. 매번 이미지를 프록시하면 함수 실행 시간과 대역폭 사용량이 증가해서 트래픽이 늘면 비용이 폭증할 수 있다.
하지만 방법 3은 빌드 시 1회만 처리하므로 런타임 비용이 0원이다.
3. WebP 변환으로 추가 최적화
단순히 이미지를 저장하는 것을 넘어, 빌드 시점에 WebP로 변환할 수 있다는 게 큰 장점이었다.
- 원본 PNG: 500KB
- WebP 85% 품질: 150KB (70% 감소)
- 화질은 거의 동일
이는 모바일 사용자의 데이터 사용량을 크게 절약하고, Lighthouse 점수도 높일 수 있다.
단점과 트레이드오프
물론 단점도 존재한다.
- 이미지를 변경할 때마다 재배포 필요
- 빌드 시간이 조금 늘어남 (게시글이 많아지면 얼마나 늘어날지 모르겠긴함..)
하지만 블로그 특성상 이미지 변경은 빈번하지 않고, 성능과 비용 절감 효과가 단점을 충분히 상쇄한다고 판단했다.
그리고 이 과정에서 이미지 처리를 위해 Node.js 생태계에서 가장 인기 있는 Sharp 라이브러리를 선택했다.
이 부분에 대해서는 Notion API의 이미지 만료로 인한 이미지 깨짐 이슈를 해결한 과정을 좀 더 자세히 풀어볼 예정이다.
마무리
이번에 때마침 좋은 스터디 기회로 그동안 미루고 미뤘던 블로그를 만들어봤는데 나름 짧은 시간이지만 많은 고민을 해보며 만들 수 있어서 좋았다.
그리고 이 블로그를 기반으로 좀더 다양한 작업들이 아직 많이 남아있는데 공부 목적으로도 테스트 해볼 수 있는 플레이그라운드가 생긴 것 같아 만족스럽다.
앞으로는 기술 블로그가 아니라 ‘나의 생각’을 기록하는 공간으로 글들을 써보려고 한다.