Google Spread Sheets로 모두가 관리할 수 있는 다국어 시스템 만들기
기존 다국어 시스템에서 발생하던 문제를 Google Spread Sheets를 활용해 해결한 경험을 공유합니다.
들어가며
서비스가 글로벌로 확장되기 시작하면 다국어는 단순히 번역 문자열을 관리하는 문제가 아니게 된다.
문구 하나를 바꾸는 일처럼 보여도 실제로는 누가 수정할 수 있는지, 어떤 경로로 반영되는지, 서비스는 그 변경을 어떻게 안정적으로 읽어야 하는지까지 전부 고려해야한다.
현재 맡고있는 프로젝트에서의 기존 다국어 시스템은 번역키 하나를 바꾸려면 개발자가 직접 개입해야 했고, 번역 데이터는 여러 군데 흩어져 있었으며, SSR 환경에서는 번역 키가 그대로 노출되는 문제도 있었다.
이 글에서는 어떤 문제가 있었는지, 왜 구글 스프레드 시트를 선택했는지, 그래서 프론트엔드에서 어떻게 이 문제를 해결했는지, 그리고 결과적으로 무엇이 달라졌는지를 순서대로 정리해보려고 한다.
1. 어떤 문제가 있었을까?
파편화된 번역 데이터로 인한 업무 프로세스 병목
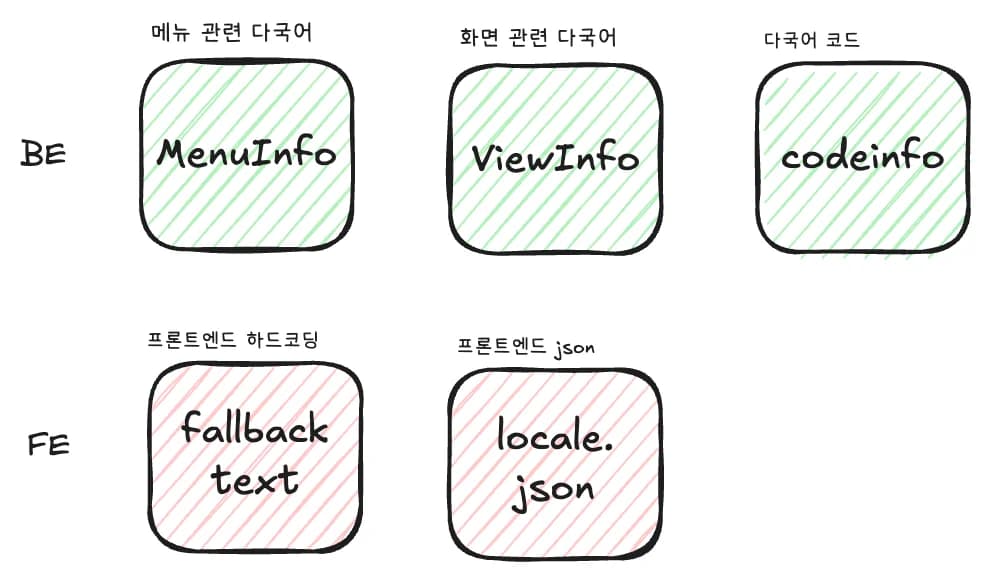
가장 먼저 문제였던 건 번역 데이터가 한 곳에 모여 있지 않았다는 점이었다.
일부는 DB 테이블에 있었고, 일부는 프론트엔드 로컬 JSON에 있었고, 일부는 로컬스토리지에 있었고, 어떤 경우에는 화면 단에서 fallback 문자열로 남아 있었다.
이런 상태에서는 특정 키가 어디에서 관리되는지 찾는 것부터 어렵다. 중복 키가 생기거나 특정 언어가 누락되기도 쉽고, 수정이 한쪽에만 반영돼서 정합성이 깨지는 일도 반복된다.
문제는 이 파편화가 결국 업무 프로세스 병목으로 이어진다는 점이었다.
기획자나 QA가 문구 하나를 수정하고 싶어도 직접 손댈 수 없었고, 결국 개발자에게 요청이 들어왔다. 개발자는 백엔드 DB를 수정하거나 프론트엔드 쪽 로직을 건드려야 했고, 작은 문구 변경도 티켓과 배포를 타게 됐다.
텍스트 수정인데 실제로는 기능 배포처럼 움직이고 있었던 셈이다.
이 구조에서는 자연스럽게 병목이 생긴다. 개발자는 운영성 작업에 시간을 쓰게 되고, PM이나 QA는 빠르게 수정할 수 없고, 작은 수정도 쌓이면 배포 사이클을 기다려야 한다. 결국 다국어는 관리 가능한 콘텐츠가 아니라 개발자가 대신 처리하는 운영 데이터가 돼버렸다.
프론트엔드 SSR 환경에서 발생하는 기술적 결함
기존 프론트엔드는 DB에서 받아온 다국어 데이터를 로컬스토리지에 저장해두고, 이후에는 그 값을 읽어서 렌더링하는 방식이었는데, Next.js SSR에서는 서버가 브라우저의 로컬스토리지를 알 수 없다.
즉 초기 렌더링 시점에는 번역 데이터가 없는 상태가 되고, 그 결과 번역 키가 그대로 노출되거나 hydration 이후에만 문구가 바뀌는 문제가 생겼다. 화면에 따라 깜빡임도 있었고, SSR 결과와 CSR 결과가 달라질 위험도 계속 남아 있었다.
문제는 이런 이슈가 한두 군데에서 끝나지 않았다고, 프로젝트 곳곳에 같은 방식이 퍼져 있었기 때문에, 화면을 보다가 번역 키 노출 문제가 발견될 때마다 티켓을 만들고, 이슈라이징을 하고, QA를 하고, 다시 배포해야 하는 상황이 반복됐다.
2. 그래서 어떻게 해결했을까?
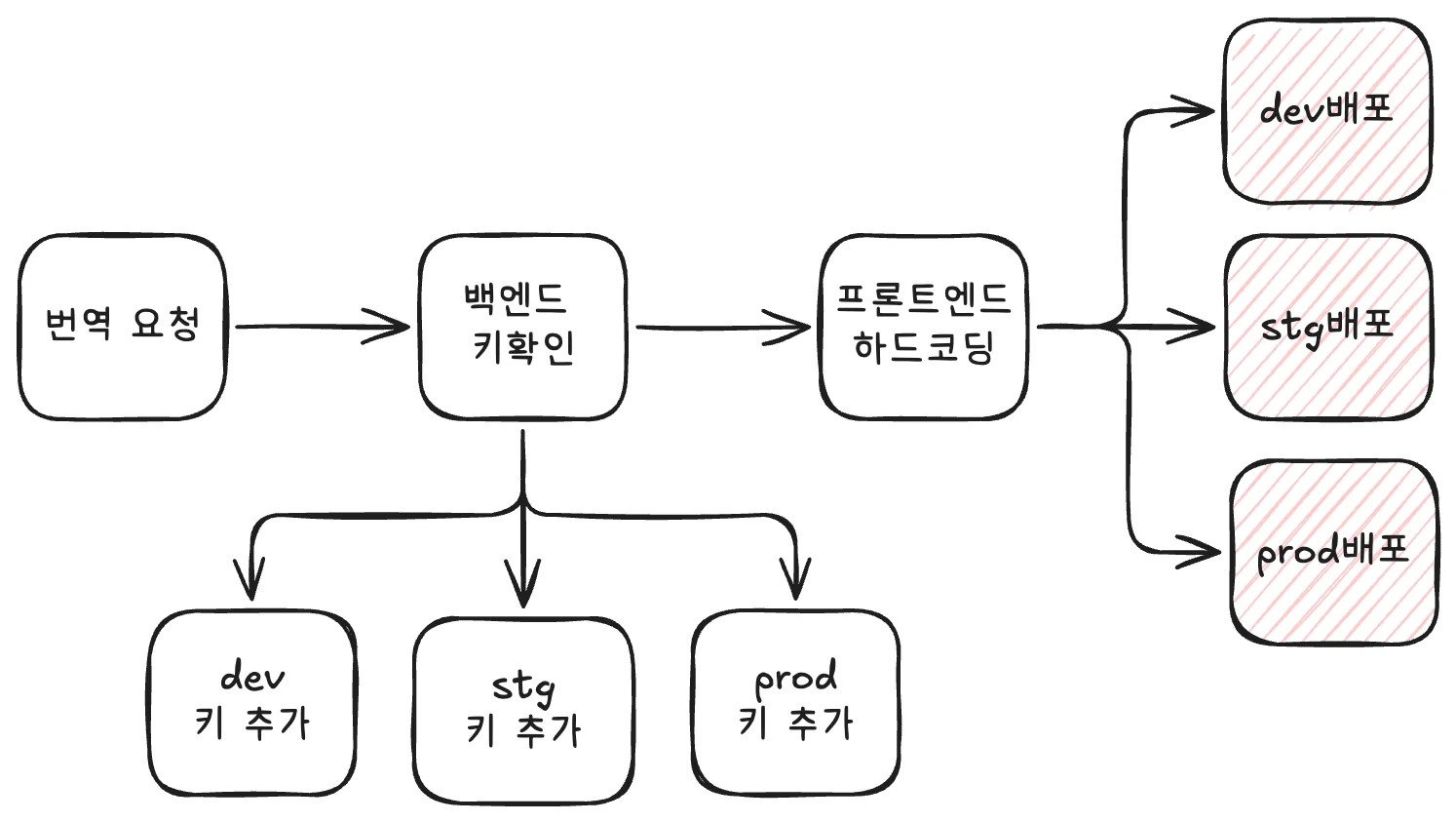
먼저 파편화된 번역 데이터를 한 곳으로 모으고 싶었다. 그래서 번역 수정의 입력 창구를 Google Sheets로 통일했다.
Google Sheets를 선택한 이유는 아마 접근성과 사용성이지 않을까 싶다.
- 누구나 바로 사용할 수 있고
- 변경 이력도 남고,
- 별도의 어드민을 만드는 것보다 훨씬 빠르게 도입할 수 있다
다만 Google Sheets를 서비스가 직접 읽는 런타임 저장소로 쓰지는 않았다.
처음에는 스프레드시트 API를 직접 붙여서 일정 주기마다 롱 폴링처럼 갱신하는 방식도 생각했다. 그런데 이 방식은 API를 계속 호출해야 해서 비용도 들고, 응답 속도도 느리고, 결국 프론트엔드에서 번역 데이터가 실제로 반영되기까지 시간이 길어지는 문제가 있었다.
그래서 Sheets는 사람이 수정하는 원본 저장소로 두고, 실제 서비스는 배포된 정적 산출물을 S3에 업로드하여 읽게 했다. 수정은 편하게 하되, 런타임은 더 안정적인 소스를 바라보게 구축했다.
이렇게 번역데이터 원본(Sheets)랑 산출물(S3 Json)을 분리해두면 운영은 쉽게 가져갈 수 있고, 서비스는 더 안정적인 런타임 구조를 가질 수 있다.
Google Apps Script로 i18n 배포 아키텍처 구성하기
Google Sheets를 CMS로 사용하기로 했다면 그 다음 질문 “시트에 있는 데이터를 어떻게 서비스가 바로 읽을 수 있는 형태로 배포할 것인가?” 였다.
이걸 해결하기 위해 Google Apps Script로 배포 파이프라인을 만들었다. 시트 상단에 커스텀 메뉴를 추가하고, 배포 버튼을 누르면 실제로 S3 업로드가 수행되도록 구성했다.
GAS를 활용한 전체적인 파이프라인 구성
대략적인 파이프라인은 아래와 같다

배포 대상은 시트 이름과 언어를 기준으로 관리했다.
const CONFIG = {
targetSheets: ["WD", "ST"],
targetLanguages: ["ko", "en", "ja"],
region: "ap-northeast-2"
};이렇게 해두면 어떤 데이터가 어떤 경로로 배포되는지 추적하기가 쉽다.
실제 배포 진입점은 사용자가 배포 버튼을 누르면 실행되는 onReleaseButton() 함수이다.
이 함수에서는 새 버전을 만들고, 시트 데이터를 언어별 JSON으로 변환하고, 번역 본문을 S3에 업로드하고, 최신 버전을 가리키는 version.json도 같이 업로드했다. 그리고 Slack 알림과 스프레드시트 로그 기록까지 한 번에 처리했다.
핵심만 남기면 대략적으로 이런 구조다.
function onReleaseButton() {
const newVersion = Date.now().toString();
const user = Session.getActiveUser().getEmail();
CONFIG.targetSheets.forEach(sheetName => {
CONFIG.targetLanguages.forEach(lang => {
const jsonData = generateJsonForSheet_(sheetName, lang);
if (!jsonData) return;
// 번역 본문은 버전별 JSON으로 저장
const s3Key = `locale/${lang}/${sheetName.toLowerCase()}/${newVersion}.json`;
uploadToS3Native_(bucketName, s3Key, jsonData, accessKey, secretKey);
});
});
// 현재 서비스가 바라봐야 할 최신 버전 포인터
uploadToS3Native_(
bucketName,
"locale/version/version.json",
JSON.stringify({ version: newVersion, updatedBy: user }, null, 2),
accessKey,
secretKey
);
sendSlackNotification_(slackUrl, newVersion, user);
metaSheet.appendRow([new Date(), newVersion, user]);
// ...
}여기서 중요했던 건 번역 본문과 최신 버전 포인터를 분리한 점이었다.
번역 본문은 locale/{lang}/{sheet}/{version}.json 경로에 버전별 파일로 쌓고, 실제 서비스가 바라봐야 할 현재 버전은 locale/version/version.json에 따로 기록했다.
이렇게 해두면 번역 데이터 자체는 버전별로 보존할 수 있고, 실제 반영은 version.json만 바꾸면 된다. 프론트엔드 입장에서도 전체 번역 파일을 매번 다시 받을 필요 없이, 먼저 작은 메타데이터 파일만 확인해서 변경 여부를 판단할 수 있다.
시트 데이터를 실제 서비스에서 읽을 수 있는 JSON으로 바꾸는 과정도 필요했다.
이때 사용한 함수가 generateJsonForSheet_() 이다.
function generateJsonForSheet_(sheetName, lang) {
const values = sheet.getDataRange().getValues();
const header = values[0].map(h => String(h).trim().toLowerCase());
const keyIdx = header.indexOf("key");
const langIdx = header.indexOf(lang.toLowerCase());
const out = {};
for (let i = 1; i < values.length; i++) {
const keyPath = String(values[i][keyIdx] || "").trim();
const value = String(values[i][langIdx] || "").trim();
// key path를 기준으로 nested JSON 생성
if (keyPath) assignNestedKey_(out, keyPath, value);
}
return JSON.stringify(out);
// ...
}예를 들어 시트가 아래처럼 되어 있으면,
key | ko | en
common.save | 저장 | Save
common.cancel | 취소 | Cancel최종적으로는 이런 JSON이 만들어진다.
{
"common": {
"save": "저장",
"cancel": "취소"
}
}런타임 입장에서는 바로 쓰기 쉬운 형태고, key namespace도 자연스럽게 관리할 수 있었다.
배포 가시성을 위한 메타데이터 알림 추가
배포 자동화에서 의외로 중요했던 건 누가 뭘 배포했는지 추적할 수 있어야 한다는 점이었다.
그래서 _metadata 시트를 따로 두고 최근 업데이트 시각, 최신 버전, 작업자를 같이 기록했다. 배포가 끝나면 Slack Webhook으로도 버전과 업데이트 시각, 작업자를 전송했다.
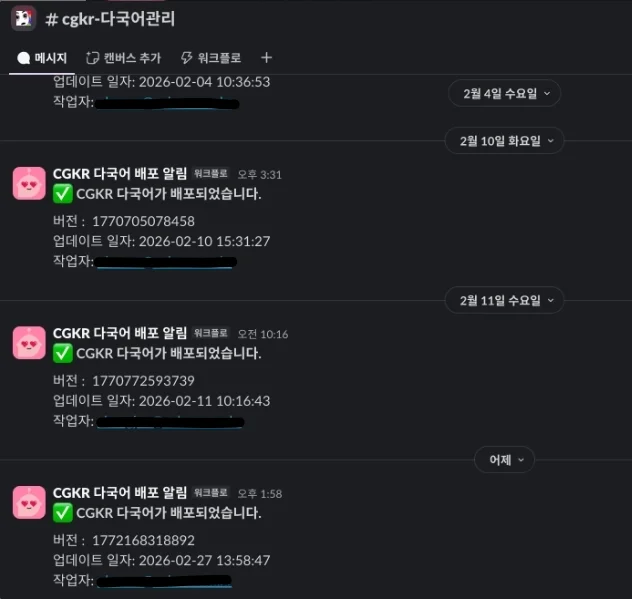
이 기록은 단순히 알림을 보내는 용도가 아니라 누가 배포했는지 바로 확인할 수 있고, 특정 버전이 언제 올라갔는지 추적할 수 있고, 잘못된 번역이 나갔을 때 원인 파악도 훨씬 빨라진다.
i18n 실시간 동기화를 위한 프론트엔드 아키텍쳐
실제 사용자 경험은 프론트엔드가 번역 데이터를 언제 읽고, 어떻게 캐싱하고, SSR과 CSR 상태를 어떻게 맞출지 고민을 했다.
여기서는 크게 세 가지 전략을 썼다.
먼저 5분마다 전체 번역 파일을 다시 요청하지 않고, 현재 최신 버전을 가리키는 메타데이터만 확인하게 했다.
const VERSION_POLLING_INTERVAL = 5 * 60 * 1000; // 5분
export function startVersionPolling(onVersionChanged) {
if (typeof global === "undefined" || global.__versionPollingInterval) return;
global.__versionPollingInterval = setInterval(async () => {
const { fetchTranslationVersion } = await import("../api/fetchTranslationVersion");
const currentVersion = await fetchTranslationVersion();
const previousVersion = global.__translationVersion;
if (currentVersion) {
global.__translationVersion = currentVersion;
// 메타데이터 버전이 바뀐 경우에만 후속 갱신 트리거
if (previousVersion && previousVersion !== currentVersion) {
onVersionChanged?.(currentVersion, previousVersion);
}
}
// ...
}, VERSION_POLLING_INTERVAL);
}이렇게 하면 변경 여부 확인 비용이 작고, 네트워크 낭비도 적다.
핵심은 매번 전체 번역을 재동기화하는 게 아니라, 바뀌었는지만 자주 확인하고 바뀐 경우에만 실제 데이터를 다시 받는 데 있다.
그리고 실제 번역 본문은 현재 캐시에 저장된 버전과 최신 버전을 비교해서 다를 때만 다시 읽도록 했다.
export function isVersionChanged(languageTypeCd) {
const cached = global.__translationsCache?.get(`translations:${languageTypeCd}`);
if (!cached || !cached.version) return false;
const currentVersion = global.__translationVersion;
return cached.version !== currentVersion;
}
export async function fetchTranslationsWithCache(languageTypeCd, forceRefresh = false) {
let currentVersion = getTranslationVersion();
if (!currentVersion) {
currentVersion = await fetchTranslationVersion() || "0";
setTranslationVersion(currentVersion);
}
const versionChanged = isVersionChanged(languageTypeCd);
if (versionChanged) {
// 캐시된 번역의 버전이 다르면 해당 언어 캐시 무효화
clearCache(languageTypeCd);
forceRefresh = true;
}
if (!forceRefresh) {
const cached = getCachedTranslations(languageTypeCd);
if (cached) return cached;
}
// 최신 버전의 JSON만 다시 fetch
const freshTranslations = await fetchTranslationsS3(languageTypeCd, currentVersion);
setCachedTranslations(languageTypeCd, freshTranslations);
return freshTranslations;
// ...
}이 구조로 바꾸고 나면 이 데이터가 최신 배포 버전인지를 기준으로 판단하게 된다. 운영 데이터에서는 시간이 아니라 버전이 더 믿을 만한 기준이라고 생각한다.
또한 번역 데이터는 자주 바뀌지 않는 정적 데이터라서 요청마다 새로 읽는 건 비효율적이었다.
그래서 캐시된 데이터를 우선 반환하고, 일정 시간이 지나면 백그라운드에서 revalidation을 수행하도록 했다. 지금 생각해보니 stale-while-revalidate에 가깝다.
const REVALIDATE_INTERVAL = 24 * 60 * 60 * 1000; // 24시간
export function getCachedTranslations(languageTypeCd, revalidateFn = null) {
const cached = global.__translationsCache?.get(`translations:${languageTypeCd}`);
if (!cached) return null;
const timeSinceRevalidation = Date.now() - cached.lastRevalidated;
if (timeSinceRevalidation >= REVALIDATE_INTERVAL && revalidateFn) {
// 응답은 기존 캐시를 먼저 주고, 뒤에서만 갱신
revalidateFn(languageTypeCd).catch(() => {});
}
return cached.data;
}
// ...이렇게 해두면 사용자는 빠르게 응답을 받고, 시스템은 뒤에서 최신 데이터를 준비할 수 있고, 캐시가 영구히 stale 상태로 남는 것도 어느 정도 막을 수 있다. 성능과 최신성 사이에서 현실적으로 균형을 잡는 방식이었다.
전체적인 아키텍쳐는 다음과 같이 간단하게 설계했다.
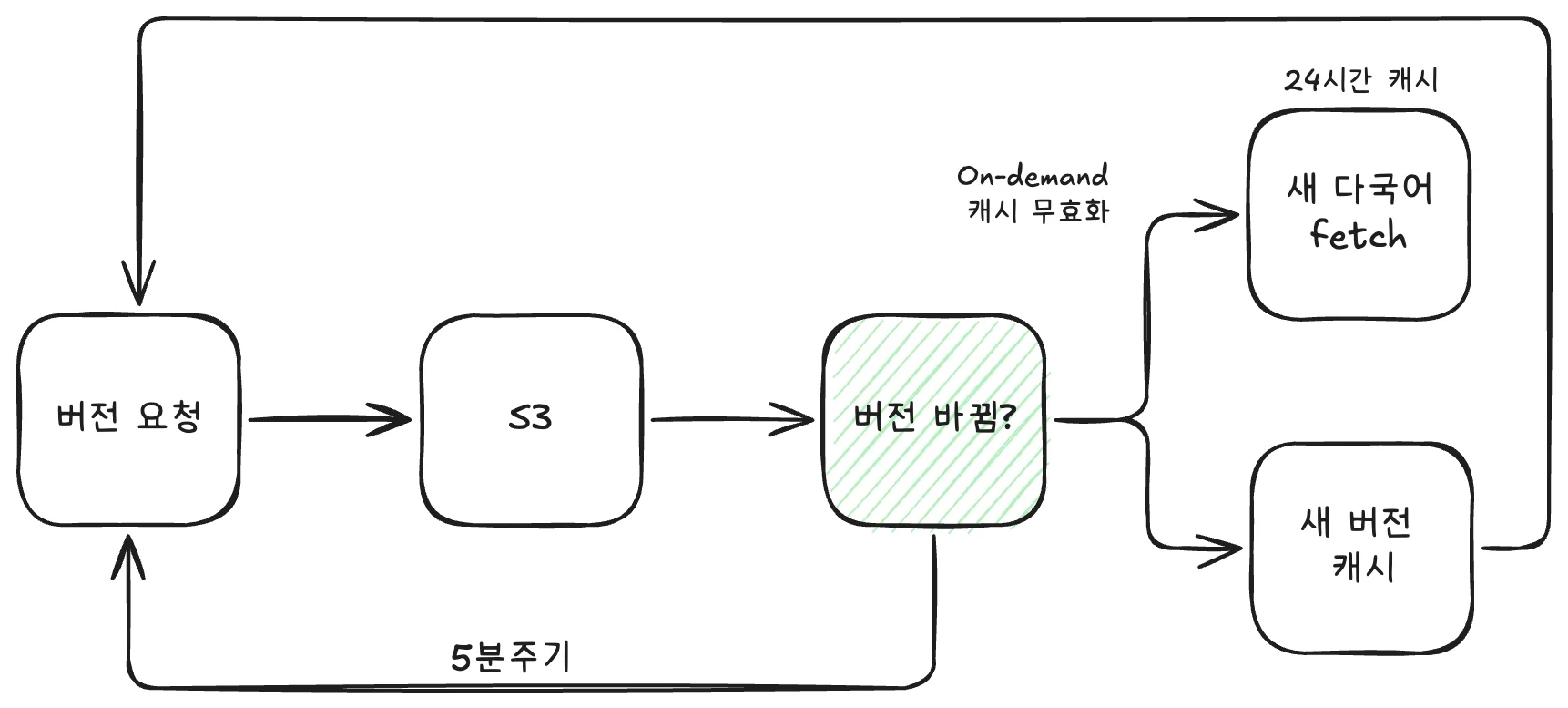
이제 SSR 진입 시점에 서버에서 받아온 초기 번역 데이터를 애플리케이션 전체에 주입해서 사용했다.
AST Codemod를 이용한 레거시 제거 자동화
이제 아키텍쳐는 잘 구상했는데 기존 레거시 코드를 어떻게 제거할지가 큰 고민이였다. 기존 레거시 함수는 573개의 파일에 7583줄의 코드라인으로 구성되어있었는데 이걸 수동으로 제거하는건 매우 많은 리소스와 비용이 필요했다.
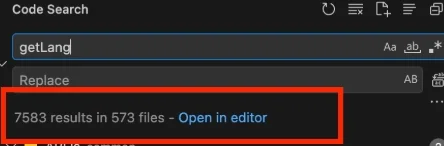
이 문제를 해결하기 위해 AST(Abstract Syntax Tree) 기반의 Codemod 스크립트를 제작했다.
왜 Regex가 아니라 AST였냐면, 문자열 수준에서는 비슷해 보여도 코드 문맥은 전혀 다를 수 있기 때문이다.
getLang("WD000105")
getLang(dynamicKey)이 두 코드는 겉으로는 비슷하지만 변환 전략이 다를 수 있다. 특히 아래처럼 모듈 레벨에서 평가되는 코드는 더 위험하다.
const COLUMNS = [{ headerName: getLang("WD000105") }];이걸 단순히 정규식을 활용해 t()로 치환하면 훅 사용 규칙을 깨뜨릴 수 있다.
즉 이 작업은 단순 치환이 아니라, 이 호출이 React 컴포넌트 내부인지, 훅 내부인지, 모듈 스코프인지, fallback 패턴이 있는지, useTranslation을 주입할 수 있는 위치인지까지 같이 판단해야 했다.
Codemod는 대략 이런 순서로 동작하게 만들었다.
먼저 컴포넌트나 훅 문맥인지 확인하고 → getLang() 호출 패턴을 찾고 → t() 호출로 바꾸고 → 필요한 useTranslation import와 훅 선언을 자동으로 넣고 → 더 이상 필요 없는 getLang import를 제거하는 방식이다.
// 대충 컴포넌트 내부인지 확인하는 안전장치
if (!isInsideComponentOrHook(path)) return;
// AST 노드 교체: getLang -> t
const newCall = t.callExpression(t.identifier("t"), [codeArg, fallbackArg]);
path.replaceWith(newCall);그리고 위험한 케이스를 무리해서 자동화하는 것보다, 안전한 범위를 빠르게 처리하고 위험한 일부는 사람이 검토할 수 있게 남겨두는 게 더 낫다고 생각해서 모듈 레벨 상수나 동적 키 조합 같은 케이스는 보수적으로 다뤘다. (거의 제거하지 않음)
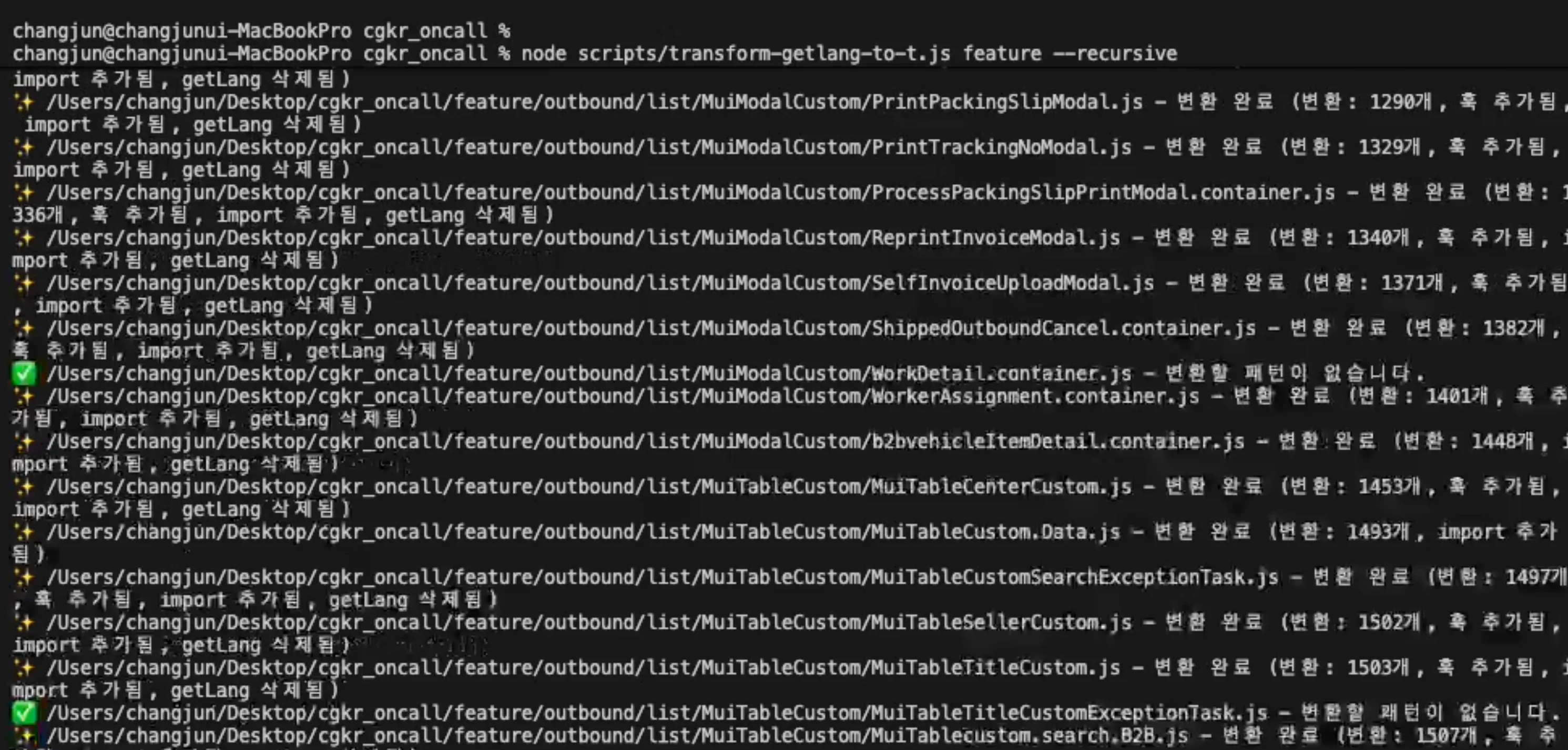
그 결과 580개의 파일에서 사용하는 7600줄의 코드라인을 단 몇분만에 교체할 수 있었다.
3. 그래서 우리팀은 무엇이 달라졌는가?
가장 먼저 달라진 건 번역 수정이 더 이상 개발 배포가 아니게 됐다는 점이었다.
이제 백엔드 개발자의 DB 수정 없이 PM과 QA, 혹은 다른 개발자들도 Google Sheets에서 직접 번역을 수정하고 배포할 수 있다. 개발자는 반복적인 운영 작업에서 빠지고, 더 중요한 문제에 집중할 수 있게 됐다.
프론트엔드에서는 SSR 환경에서 초기 렌더링 품질이 확실히 좋아졌다.
기존처럼 로컬스토리지 의존 때문에 번역 키가 그대로 노출되는 문제가 줄었고, 서버가 먼저 번역 데이터를 읽어 렌더링하도록 구조를 바꾸면서 초기 화면 품질도 안정화됐다.
레거시 마이그레이션 비용도 크게 줄었다.
수동으로 며칠이 걸릴 작업을 AST codemod로 몇 분 단위까지 줄일 수 있었고, 그 과정에서 휴먼 에러 가능성도 함께 낮출 수 있었다.
결국 이번 작업은 단순히 번역 관리 도구를 바꾼 게 아니라 개발자 경험, 기술 부채 해결, 업무 프로세스 개선 세마리 토끼를 잡을 수 있었던 경험이였다.
4. 마무리
이번 작업을 하면서 가장 크게 느낀 건 다국어 시스템의 핵심이 번역 문자열 그 자체가 아니라는 점이었다.
실제로 중요한 건 누가 수정할 수 있는지, 어떻게 배포되는지, 서비스는 최신 데이터를 어떻게 판단하는지, SSR과 CSR은 같은 상태를 어떻게 바라보게 할 것인지 같은 문제였다.
i18n도 결국 콘텐츠이고 관리 대상이다. 비개발자도 운영할 수 있어야 하고, 데이터 흐름이 단일화돼 있어야 하고, 최신 버전을 안정적으로 감지할 수 있어야 한다.
이번 개선을 통해 얻은 결론을 정리해보면
- Google Sheets는 번역 관리 도구로 충분히 좋다.
- 다만 런타임은 배포된 정적 산출물을 읽어야 한다.
- 그 사이에는 version metadata, 캐시 전략, SSR 동기화 같은 장치가 꼭 필요하다.
- 대규모 레거시 제거 역시 자동화 없이는 비용이 너무 크다.
결국 엔지니어링의 역할은 기능을 구현하는 데서 끝나지 않고, 팀 전체가 더 적은 비용으로 더 안전하게 운영할 수 있는 구조를 만드는 데까지 이어진다는 걸 다시 느꼈다.
참고자료
https://www.dev-bbak.site/blog/DEV/intl-automation
https://tech.inflab.com/20250206-i18n-automation/